

Small Language Models: The Smarter, Faster AI Revolution Nobody Is Talking About
Everyone is chasing bigger AI models. But in 2026, the smartest companies are going smaller — and winning. Here is the complete guide to Small Language Models, why they are disrupting the AI landscape, and why they might be the most practical AI investment your business can make.
Small Language Models — commonly referred to as SLMs — are one of the most significant and most underreported shifts happening in artificial intelligence right now. While the technology world has spent the past three years captivated by the race to build ever-larger AI models with hundreds of billions of parameters, a quiet but powerful counter-movement has been gaining serious momentum: the realization that smaller, more focused, more efficient AI models can match or even outperform their massive counterparts on the specific tasks that actually matter to most businesses — at a fraction of the cost, with a fraction of the infrastructure, and with capabilities that giant models simply cannot offer, like running entirely on a single device without any cloud connection.
The implications of this shift are enormous. For years, cutting-edge AI capability was the exclusive domain of organizations that could afford the enormous compute costs of training and running giant models — effectively locking out smaller businesses, privacy-sensitive industries, and resource-constrained environments. Small Language Models are democratizing access to genuine AI capability in a way that large models never could.
In this article, we break down exactly what Small Language Models are, how they differ from large language models, what makes them so compelling in 2026, where they are being deployed, and how your organization can start taking advantage of them today.
What Are Small Language Models? A Clear Definition
A language model is an AI system trained on large amounts of text data to understand and generate human language. Large Language Models — or LLMs — like GPT-4, Claude, and Gemini Ultra contain hundreds of billions of parameters and require massive computing infrastructure to train and run. They are extraordinarily capable general-purpose systems, but they come with equally extraordinary costs and constraints.
Small Language Models occupy a different point on the capability-efficiency spectrum. While there is no single universally agreed definition of what makes a model small, SLMs are generally understood to have between one billion and around thirteen billion parameters — dramatically smaller than frontier LLMs, but still powerful enough to perform impressively on a well-defined range of tasks.
The key insight behind SLMs is that most real-world AI applications do not need a general-purpose model capable of writing poetry, solving advanced mathematics, and holding philosophical conversations simultaneously. They need a model that is very good at one specific thing — summarizing customer feedback, classifying support tickets, generating product descriptions, extracting information from documents, answering questions about a specific knowledge base. For these focused use cases, a Small Language Model that has been carefully trained and fine-tuned for the task can match or beat a much larger model while running faster, cheaper, and with far greater privacy.
The best AI model for a job is not the biggest one available — it is the one most precisely matched to the task. Small Language Models are winning that match for most real business applications in 2026.
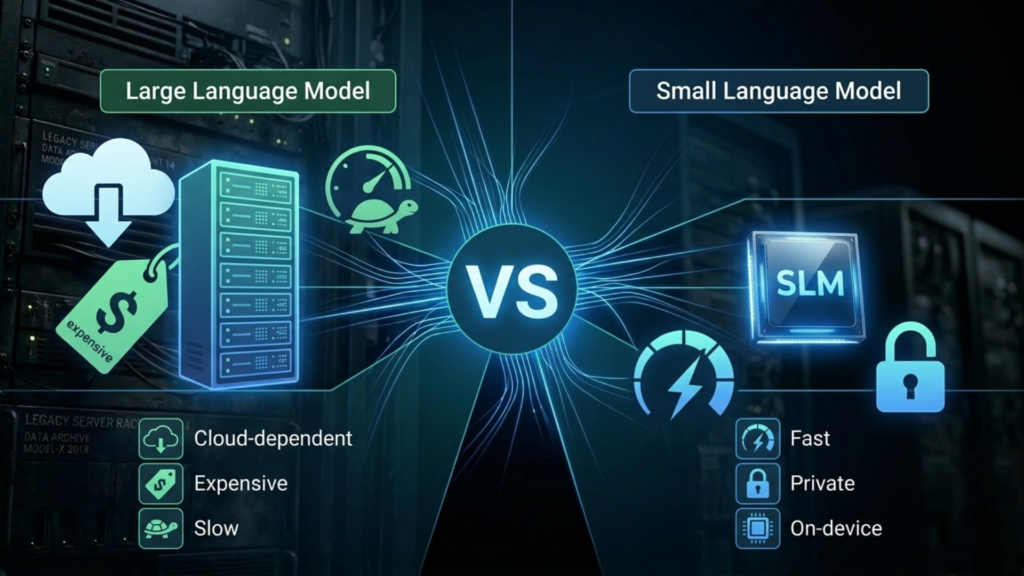
Small Language Models vs Large Language Models: What Is the Real Difference?
Understanding the practical differences between SLMs and LLMs is essential for making good AI investment decisions. Here is an honest comparison across the dimensions that matter most:
Cost
Running a frontier LLM via API costs orders of magnitude more per token than running a small model — especially one deployed on your own infrastructure. For applications that process millions of documents, handle thousands of customer interactions per day, or run continuous background analysis, the cost difference between an LLM and an SLM for the same task can be the difference between a project that is economically viable and one that is not.
Speed and Latency
Small Language Models are significantly faster than large ones, both for inference on cloud hardware and — crucially — for on-device deployment. An SLM can generate responses in milliseconds on consumer-grade hardware. This speed advantage is critical for real-time applications, user-facing interfaces where latency directly affects experience quality, and edge deployments where the model must run on a device with limited compute.
Privacy and Data Control
Perhaps the most strategically important advantage of Small Language Models is that they can run entirely on-premises or on-device — meaning sensitive data never leaves your environment. For industries dealing with medical records, legal documents, financial data, classified information, or any other sensitive content, the ability to run capable AI without sending data to a cloud provider is not a nice-to-have feature. It is a fundamental requirement. SLMs make this possible in a way that frontier LLMs, which require cloud API access, simply cannot.
Customization and Fine-Tuning
Fine-tuning a model — training it further on your own domain-specific data to make it expert in your particular context — is practical and affordable with Small Language Models. Fine-tuning a frontier LLM, by contrast, requires compute resources and costs that put it out of reach for most organizations. This means SLMs can be deeply adapted to your specific vocabulary, tone, workflows, and knowledge base in ways that produce far better results for your use case than prompting a generic giant model ever could.
Where Large Models Still Win
It is important to be honest: for genuinely complex, multi-step reasoning tasks, broad general knowledge questions, highly creative generation, and tasks that require integrating knowledge across many diverse domains simultaneously, frontier LLMs still have meaningful advantages. The right architecture for many organizations in 2026 is not SLM or LLM — it is using SLMs for the high-volume, well-defined tasks where they excel, and reserving LLM access for the genuinely complex tasks where their breadth of capability is required.

Why Small Language Models Are Exploding in Popularity in 2026
Several converging forces have made 2026 the breakout year for Small Language Models:
Dramatic Improvements in Training Efficiency
Advances in training techniques — particularly synthetic data generation, knowledge distillation from larger models, and more efficient training algorithms — have dramatically improved what small models can achieve. Microsoft’s Phi series, Google’s Gemma models, Meta’s Llama family, and Mistral’s compact models have all demonstrated that carefully trained small models can achieve performance on many benchmarks that was simply not possible for models of their size just two years ago. The capability floor for small models has risen sharply.
The Economics of Scale
As organizations move from AI experimentation to AI production — running models continuously at scale across real business operations — the economics of LLM API costs become impossible to ignore. Companies that built their initial AI features on frontier LLM APIs are finding that the cost of running those features at production scale is unsustainable, and they are migrating to smaller models for the bulk of their workload. This migration from LLMs to SLMs for production applications is one of the defining enterprise AI trends of 2026.
On-Device AI Hardware Maturity
The maturation of neural processing units in smartphones, laptops, and IoT devices has created a massive installed base of hardware capable of running Small Language Models locally. Apple Silicon, Qualcomm Snapdragon X chips, and Intel’s AI PC processors all include dedicated AI accelerators powerful enough to run SLMs at practical speeds. This hardware revolution means that SLM deployment is no longer limited to cloud servers — it can happen on the device in your pocket or on your desk.
Enterprise Privacy and Compliance Pressure
Data privacy regulations, corporate security policies, and the growing sensitivity of enterprise data have created strong institutional pressure to keep AI processing local wherever possible. Small Language Models deployed on private infrastructure satisfy these requirements in a way that cloud-dependent LLMs cannot. For healthcare providers, law firms, financial institutions, and government agencies, the privacy advantage of SLMs is driving adoption faster than any capability argument alone could.
Real-World Small Language Models Use Cases Transforming Industries
Small Language Models are not just a cost-saving measure — they are enabling entirely new categories of AI application that were impractical with large models. Here are the most compelling real-world deployments:
On-Device Personal AI Assistants
Smartphone manufacturers and operating system developers are embedding SLMs directly into devices to power AI features that work entirely offline. Apple Intelligence, Google’s on-device AI features, and Samsung’s Galaxy AI all use small models running on the device’s neural processing unit for tasks like text summarization, smart replies, writing assistance, and photo understanding. These features work without an internet connection, with no data ever leaving the device, and with response times that feel instant to the user.
Enterprise Document Intelligence
Law firms, financial institutions, and healthcare organizations are deploying fine-tuned SLMs on private infrastructure to process sensitive documents — contracts, medical records, financial reports, regulatory filings — extracting key information, generating summaries, flagging anomalies, and answering questions about document content. The combination of domain-specific fine-tuning and private deployment produces accuracy that exceeds what a generic frontier LLM accessed via cloud API could achieve, while keeping sensitive document content entirely within the organization’s control.
Customer Service and Support Automation
For customer service applications that handle high volumes of routine inquiries, SLMs fine-tuned on a company’s product documentation, policies, and historical support interactions dramatically outperform generic LLMs at a fraction of the cost. They understand company-specific terminology, know the exact details of specific products, and respond in the brand’s established voice — capabilities that require extensive and expensive prompt engineering to approximate with a generic frontier model, if they can be achieved at all.
Code Assistance and Developer Tools
Coding-specific Small Language Models — trained heavily on code rather than general text — have become powerful developer productivity tools. Models like Microsoft’s Phi-3, Google’s CodeGemma, and various open-source coding SLMs can run directly in a developer’s IDE on their local machine, providing code completion, bug detection, and explanation capabilities without sending proprietary source code to external cloud services. For enterprises with strict intellectual property protection requirements, this is an enormous advantage over cloud-based coding assistants.
Industrial and IoT Applications
Manufacturing plants, logistics operations, and industrial facilities are deploying Small Language Models on edge hardware to enable natural language interfaces for complex operational systems — allowing floor workers to query equipment status, troubleshoot problems, and access operational knowledge using plain language on devices with limited connectivity. The ability to run these models locally, without cloud dependency, is essential in industrial environments where reliable internet connectivity cannot be guaranteed.
Small Language Models: Challenges You Need to Plan For
Small Language Models offer compelling advantages — but they come with real limitations that organizations must plan around:
- Task scope limitations: SLMs perform best within a well-defined domain or task type. Asking a small model to handle tasks far outside its training distribution produces noticeably worse results than a frontier LLM. Clearly defining the scope of tasks your SLM will handle — and routing out-of-scope requests to a larger model or a human — is essential for maintaining quality.
- Fine-tuning investment: Getting the best performance from a Small Language Model for your specific use case typically requires fine-tuning on your own data. This is far more affordable than fine-tuning a frontier LLM, but it still requires investment in data curation, annotation, and the fine-tuning process itself. Organizations that deploy a generic small model without fine-tuning will be disappointed by the results.
- Evaluation complexity: Evaluating SLM performance for your specific use case requires building domain-specific evaluation datasets and benchmarks. Generic benchmark scores are a poor predictor of how a model will perform on your particular data and tasks. Investment in rigorous, use-case-specific evaluation is not optional — it is how you know whether your model is actually working.
- Model selection complexity: The SLM landscape is crowded and evolving rapidly. Choosing the right base model for your use case — considering architecture, training data, license terms, and performance profile — requires technical expertise and ongoing attention as new models are released regularly. Staying current with the fast-moving SLM ecosystem is a real operational requirement.
- Security and model protection: SLMs deployed on-premises or on-device must be protected from extraction, tampering, and adversarial attacks. Unlike cloud-hosted models where the provider handles infrastructure security, on-premises SLM deployments require organizations to implement their own model security measures.
How to Get Started With Small Language Models in Your Organization
The barrier to starting with Small Language Models is lower than most organizations realize. Here is a practical path to getting started:
- Identify Your High-Volume, Well-Defined AI Tasks
Catalog the AI-assisted tasks in your organization that happen at high volume and have clearly defined inputs and outputs. Document classification, information extraction, content summarization, FAQ answering, sentiment analysis, and structured data generation are all excellent SLM candidates. The more clearly defined the task, the better an SLM will perform.
- Evaluate Open-Source SLM Options
A rich ecosystem of high-quality open-source Small Language Models is available for experimentation and production deployment. Microsoft’s Phi-3 and Phi-4 families, Meta’s Llama 3 series, Google’s Gemma 2, and Mistral’s models all offer strong performance across a range of task types, permissive licenses for commercial use, and active community support. Start by evaluating several models against your specific use case before committing to a direction.
- Build a Domain-Specific Evaluation Dataset
Before fine-tuning or deploying any model, assemble a representative set of examples from your actual use case — inputs and ideal outputs — that you can use to measure model performance. This evaluation dataset is your ground truth for making model selection and fine-tuning decisions, and it will save you from deploying a model that looks good on generic benchmarks but performs poorly on your real data.
- Fine-Tune on Your Domain Data
Once you have selected a base model, invest in fine-tuning it on your domain-specific data. Even a relatively small fine-tuning dataset — a few thousand high-quality examples — can produce dramatic improvements in performance on your specific task compared to the base model. Techniques like LoRA and QLoRA make fine-tuning accessible on modest hardware budgets. - Deploy, Monitor, and Iterate
Deploy your fine-tuned SLM to a production environment, instrument it with monitoring for performance and quality metrics, and establish a regular cadence of evaluation and retraining as your data evolves. Small Language Models are not fire-and-forget deployments — they benefit from continuous improvement as you accumulate more domain data and user feedback.
Final Thoughts: Small Language Models Are the Practical AI Future
The narrative around artificial intelligence has been dominated by a size race — the assumption that bigger models are always better and that the path to AI capability runs through ever-larger training runs on ever-more-expensive hardware. Small Language Models are a powerful corrective to that narrative. They demonstrate that for the vast majority of real business AI applications, precision, efficiency, and fit-for-purpose design outperform raw scale.
In 2026, Small Language Models are enabling organizations of all sizes to deploy genuine AI capability in environments that frontier LLMs could never reach — on personal devices, in privacy-sensitive industries, in resource-constrained settings, and at economic scales that make production AI viable rather than aspirational.
The future of enterprise AI is not one giant model doing everything. It is an intelligent architecture of specialized models — each optimized for its specific purpose — with Small Language Models handling the high-volume, well-defined work that constitutes the vast majority of real business AI needs. The organizations that understand and embrace this architecture today will build AI capabilities that are faster, cheaper, more private, and ultimately more effective than those still waiting for a single giant model to solve all their problems.

